Experiments with Energy Signatures
One of the interesting aspects of energy management is being able to react to trends in your energy flows to optimise the way energy is used at your home or business. Understanding the patterns in a building’s energy use allows energy managers to plan and scope the kinds of energy sources needed and figure out how much money that energy will cost them today and in the future. Until recently, this has been something studied by local authorities and planners within large corporations or organisations. However, as rooftop solar systems are becoming more and more common, these energy flows are something you can actually inspect yourself. With SolarNetwork, we’ve demonstrated easy and affordable ways to roll-out energy monitoring across your home or business, using a variety of devices. Once that data is stored in SolarNet, the cloud repository, you can also get to it via the SolarQuery RESTful API from just about any development platform you choose. What we are experimenting with now is one of those applications which we’re calling SolarQuant.
SolarQuant is an application server being written in PHP and MySQL, accessing a non-linear neural network program called emergent. The aim is to produce a "point and shoot" application server that can watch the data coming from a SolarNode - whether it is a single circuit or multiple circuits - and develop an "energy signature" to characterise how energy is used or generated at that location.
emergent is only one of many open-source “deep learning” applications that “learn” based on the examples within a prepared data set. The method of how a neural network works, as I understand it, is that it is a software able to find patterns in data after being exposed to a set of “trials” which represent the examples of how a system has been performing in a certain context represented by input variables. It looks at each of these examples, and runs through them iteratively as a set, creating what are a series of weights that drive a non-linear solution to the problem. It is iterative because it aims to find the best solution by modifying those input weights to see if that helps it get closer to the solution - but it needs to run through all the examples to gauge whether this modification was an improvement. The theory is that by doing this over and over, always following what worked best last time, the neural network gains “experience” with the data, and eventually builds a model - described mostly by the weights it settles to - that may closely describe the real world as measured by the data you collected. And it’s not something that's a “rule of thumb” or a simple calculation - it is a site-specific, non-linear solution that possibly can only be approached using this empirical methodology. I don’t know if the “Three-body Problem” is a proper analogy but I always think of the fact that while two planets in space can have their orbits with relation to each other described by a formula involving their respective masses and the distance between them, there is no such formula for 3 planetary bodies. It’s not that the orbits of 3 planets cannot be found, it’s just that it relies on circumstantial, empirical data and not a formula you can plug values into. Similarly, I believe there is no real ‘formula’ to how you use or generate energy - it just depends on the day, the time, what you’re doing, what kind of loads you have and possibly what the weather is like. We’re calling that resulting pattern your energy signature because the line of energy use - mostly a continuous time series - has that kind of shape:
ARM vs. x86-64 vs. GPU
So there are a few neural network applications and they run on different processors. And on top of that, there are different ‘algorithms’ that each use to accomplish the development of correlations. In our tests, we are currently using a 3-layer network Back-Propagation algorithm which suited the task, and it is one of the most standard types of neural networks. Much more complex architectures exist today and their complexity is actively handled by what seems to be a geometric growth of faster and cheaper multi-processor machines connected in clusters.
Possibly the most interesting innovation these days for deep learning has been the use of GPUs, using software frameworks that can tap the power of their parallel processing ability. Once such software framework is called CUDA (Compute Unified Device Architecture) from nVidia. This framework has been recently supported by emergent, and from the tests carried out by members of that project, the promised acceleration versus CPU is compelling - possibly a 2X - 10X multiple over a 4-core Intel processor and this performance can be achieved from a rather average gaming video card. Given the timeframe needed to develop an accurate energy signature for a building, we thought it would be good to test this out with SolarQuant.
Selecting your video card At the moment, the only GPU harnessing libraries that are supported by emergent are CUDA based, which leverages the nVidia chipsets. What seems to be one measure of expected performance is the number of CUDA “cores” on the video card. Given it was an experiment, I purchased the lowest cost nVidia card I could, namely the GTX750Ti, for around $238 NZD. This device seems to have 640 cores. To put this in context, you can see the list of different nVidia adapters and their cores here. So there are clearly more powerful units out there with several thousand CUDA cores - wow! That’s something to look forward to. Given the beast of a machine that could be built to do this job, I thought we better give these machines names to keep track. So this one is going to be called Taniwha One as an 4-core X86-64 box on emergent v7 and Taniwha Two as a 640-core CUDA computer on emergent v8.
Ubuntu 16.04 and LAMP I had the most recent version of Ubuntu, 16.10, loaded on a 3.4Ghz quad-core Intel i7 2600 machine, but when it came to compiling the special CUDA version of emergent, it did not work due to a change in the Qt5 webengine module which was needed for the application. So I installed in parallel a boot of Ubuntu 16.04, and also installed the CUDA 8.0 SDK available for download (quite large I thought at 1.9GB, but nothing major these days with broadband) from nVidia for Ubuntu 16.04 here. I followed the Build Linux directions for emergent here but with the added argument to the ./configure command:
--cuda
It chugged away for quite a while, but once it finished I set my environmental variable for LD_LIBRARYPATH using my .bashrc file:
export LD_LIBRARY_PATH=$HOME/lib:/usr/lib:/usr/local/lib:$LD_LIBRARY_PATH
And rebooted. I was then able to login and type into a command prompt window:
emergent_cuda
and up came the familiar GUI development toolset - but it looked pretty stylish this time compared with version 7. One of the interesting aspects of energy management is being able to react to trends in your energy flows to optimise the way energy is used at your home or business. Understanding the patterns in a building’s energy use allows energy managers to plan and scope the kinds of energy sources needed and figure out how much money that energy will cost them today and in the future. Until recently, this has been something studied by local authorities and planners within large corporations or organisations. However, as rooftop solar systems are becoming more and more common, these energy flows are something you can actually inspect yourself. With SolarNetwork, we’ve demonstrated easy and affordable ways to roll-out energy monitoring across your home or business, using a variety of devices. Once that data is stored in SolarNet, the cloud repository, you can also get to it via the SolarQuery RESTful API from just about any development platform you choose. What we are experimenting with now is one of those applications which we’re calling SolarQuant.
SolarQuant is an application server being written in PHP and MySQL, accessing a non-linear neural network program called emergent. The aim is to produce a "point and shoot" application server that can watch the data coming from a SolarNode - whether it is a single circuit or multiple circuits - and develop an "energy signature" to characterise how energy is used or generated at that location.
emergent is only one of many open-source “deep learning” applications that “learn” based on the examples within a prepared data set. The method of how a neural network works, as I understand it, is that it is a software able to find patterns in data after being exposed to a set of “trials” which represent the examples of how a system has been performing in a certain context represented by input variables. It looks at each of these examples, and runs through them iteratively as a set, creating what are a series of weights that drive a non-linear solution to the problem. It is iterative because it aims to find the best solution by modifying those input weights to see if that helps it get closer to the solution - but it needs to run through all the examples to gauge whether this modification was an improvement. The theory is that by doing this over and over, always following what worked best last time, the neural network gains “experience” with the data, and eventually builds a model - described mostly by the weights it settles to - that may closely describe the real world as measured by the data you collected. And it’s not something that's a “rule of thumb” or a simple calculation - it is a site-specific, non-linear solution that possibly can only be approached using this empirical methodology. I don’t know if the “Three-body Problem” is a proper analogy but I always think of the fact that while two planets in space can have their orbits with relation to each other described by a formula involving their respective masses and the distance between them, there is no such formula for 3 planetary bodies. It’s not that the orbits of 3 planets cannot be found, it’s just that it relies on circumstantial, empirical data and not a formula you can plug values into. Similarly, I believe there is no real ‘formula’ to how you use or generate energy - it just depends on the day, the time, what you’re doing, what kind of loads you have and possibly what the weather is like. We’re calling that resulting pattern your energy signature because the line of energy use - mostly a continuous time series - has that kind of shape:
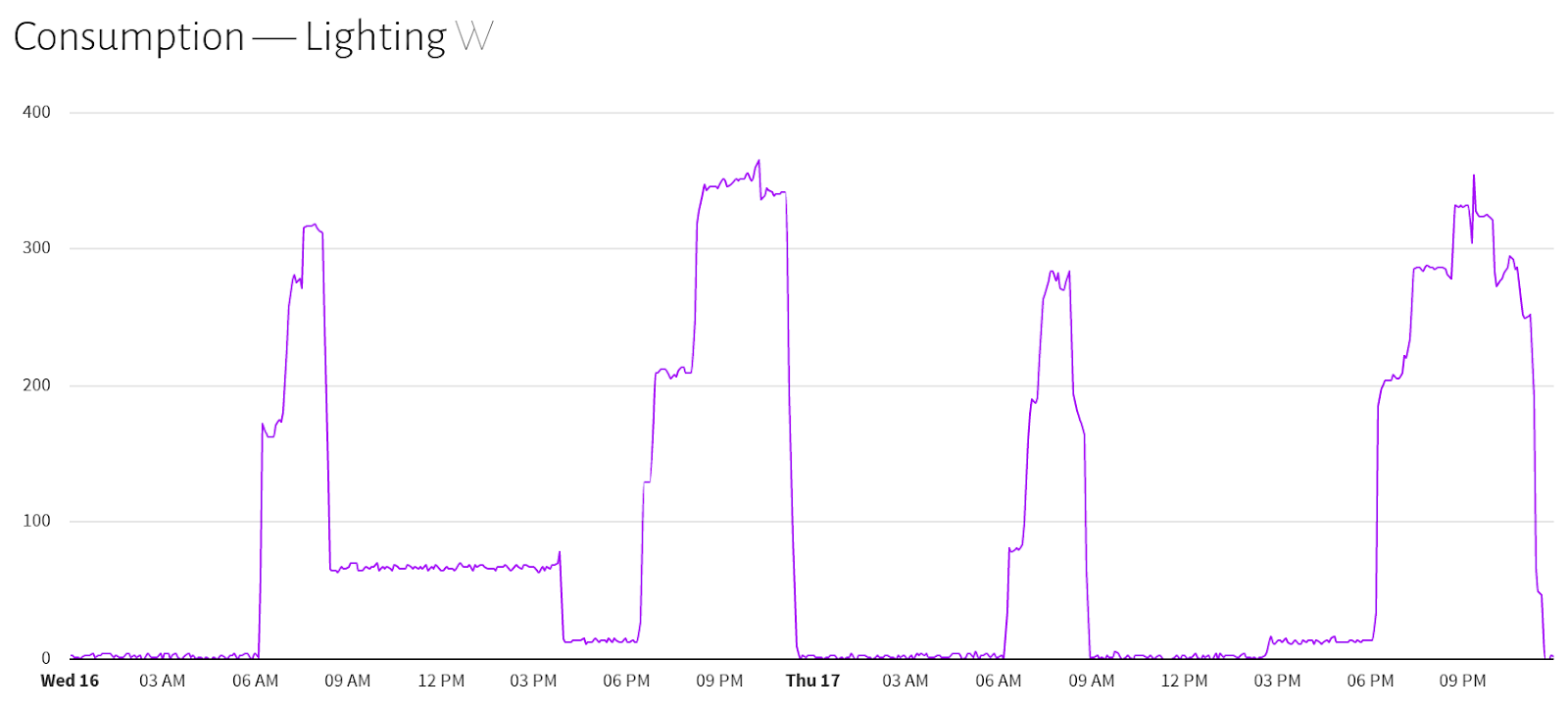 |
| Example of an Energy Signature (lighting) |
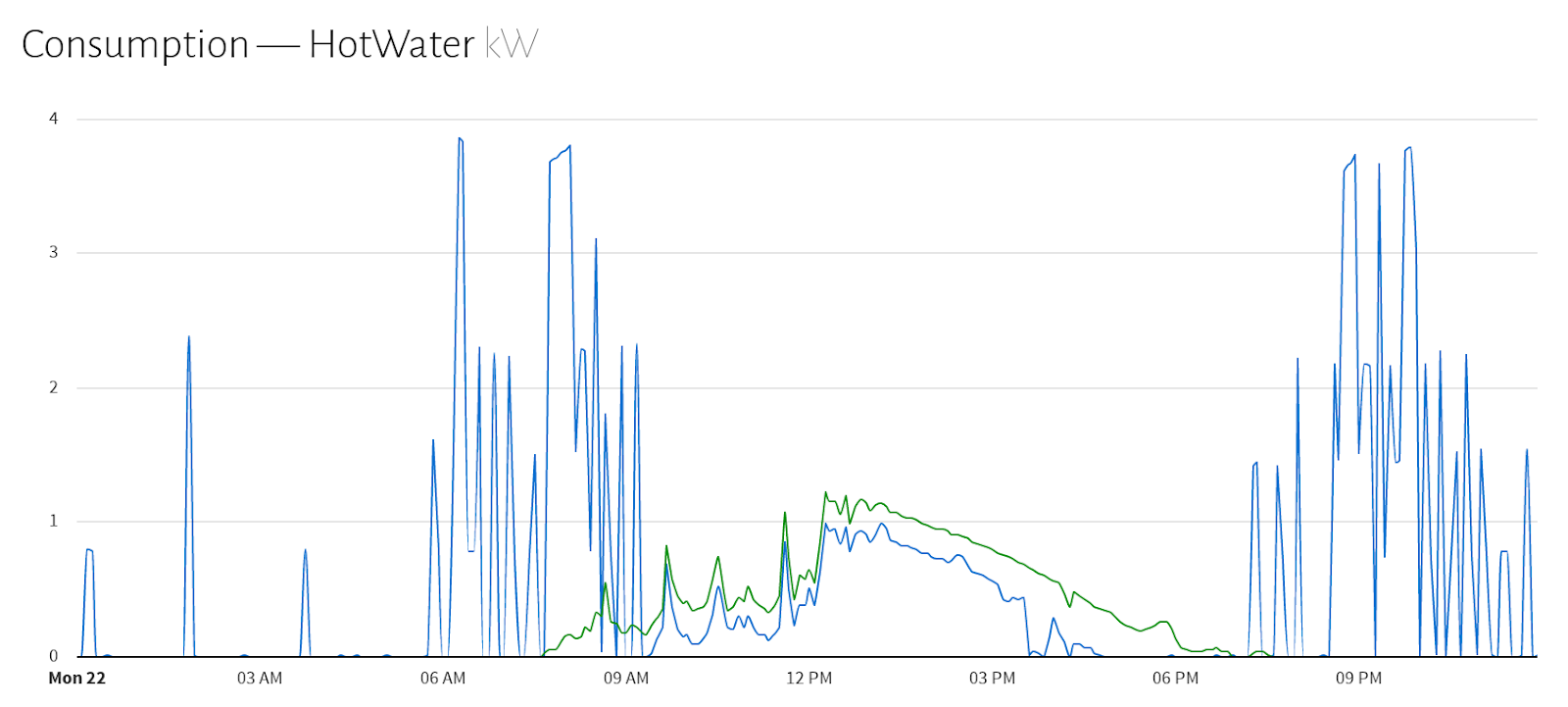 |
| Example of an Energy Signature (hot water) |
ARM vs. x86-64 vs. GPU
So there are a few neural network applications and they run on different processors. And on top of that, there are different ‘algorithms’ that each use to accomplish the development of correlations. In our tests, we are currently using a 3-layer network Back-Propagation algorithm which suited the task, and it is one of the most standard types of neural networks. Much more complex architectures exist today and their complexity is actively handled by what seems to be a geometric growth of faster and cheaper multi-processor machines connected in clusters.
Possibly the most interesting innovation these days for deep learning has been the use of GPUs, using software frameworks that can tap the power of their parallel processing ability. Once such software framework is called CUDA (Compute Unified Device Architecture) from nVidia. This framework has been recently supported by emergent, and from the tests carried out by members of that project, the promised acceleration versus CPU is compelling - possibly a 2X - 10X multiple over a 4-core Intel processor and this performance can be achieved from a rather average gaming video card. Given the timeframe needed to develop an accurate energy signature for a building, we thought it would be good to test this out with SolarQuant.
Selecting your video card At the moment, the only GPU harnessing libraries that are supported by emergent are CUDA based, which leverages the nVidia chipsets. What seems to be one measure of expected performance is the number of CUDA “cores” on the video card. Given it was an experiment, I purchased the lowest cost nVidia card I could, namely the GTX750Ti, for around $238 NZD. This device seems to have 640 cores. To put this in context, you can see the list of different nVidia adapters and their cores here. So there are clearly more powerful units out there with several thousand CUDA cores - wow! That’s something to look forward to. Given the beast of a machine that could be built to do this job, I thought we better give these machines names to keep track. So this one is going to be called Taniwha One as an 4-core X86-64 box on emergent v7 and Taniwha Two as a 640-core CUDA computer on emergent v8.
Ubuntu 16.04 and LAMP I had the most recent version of Ubuntu, 16.10, loaded on a 3.4Ghz quad-core Intel i7 2600 machine, but when it came to compiling the special CUDA version of emergent, it did not work due to a change in the Qt5 webengine module which was needed for the application. So I installed in parallel a boot of Ubuntu 16.04, and also installed the CUDA 8.0 SDK available for download (quite large I thought at 1.9GB, but nothing major these days with broadband) from nVidia for Ubuntu 16.04 here. I followed the Build Linux directions for emergent here but with the added argument to the ./configure command:
--cuda
It chugged away for quite a while, but once it finished I set my environmental variable for LD_LIBRARYPATH using my .bashrc file:
export LD_LIBRARY_PATH=$HOME/lib:/usr/lib:/usr/local/lib:$LD_LIBRARY_PATH
And rebooted. I was then able to login and type into a command prompt window:
emergent_cuda
 |
| Emergent version 8 |
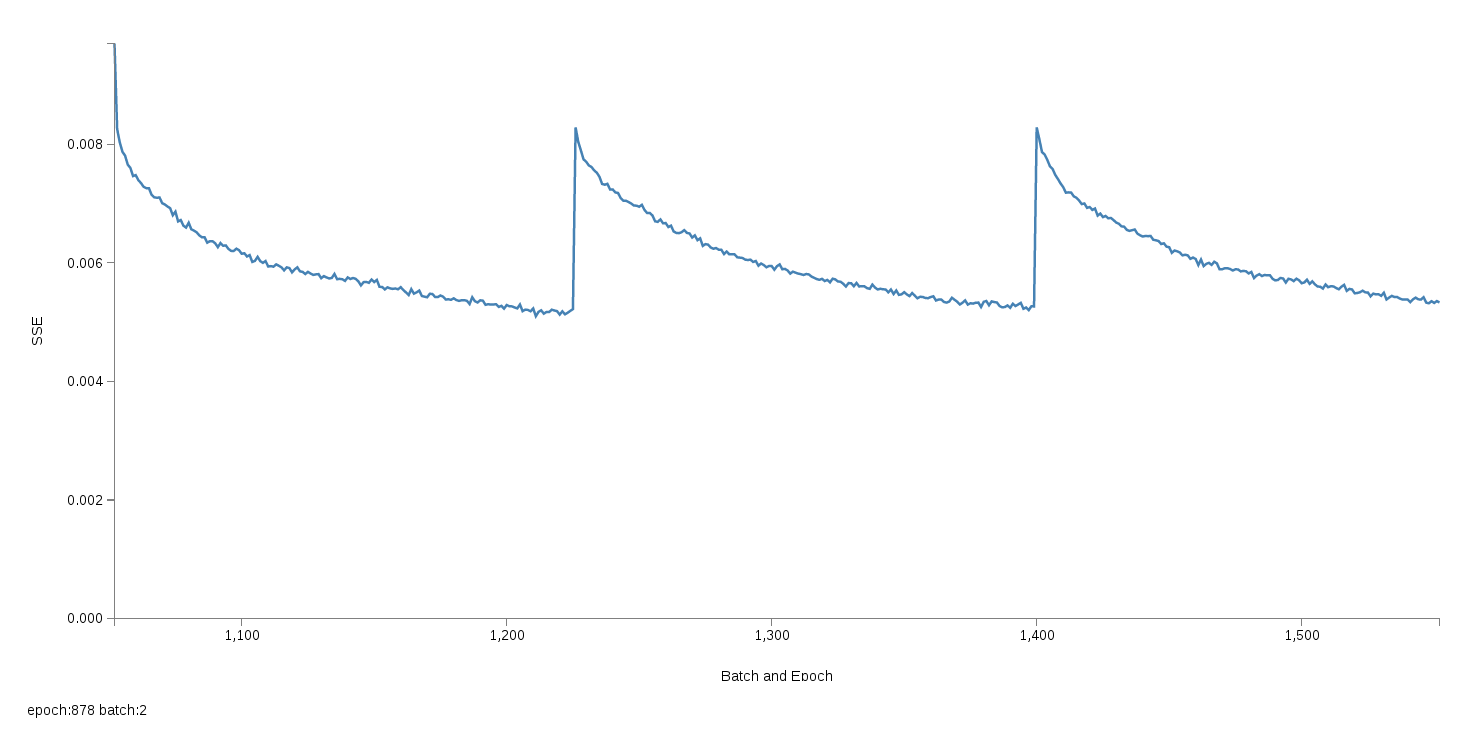 |
| 3 Batches showing falling SSE as the NN learns |
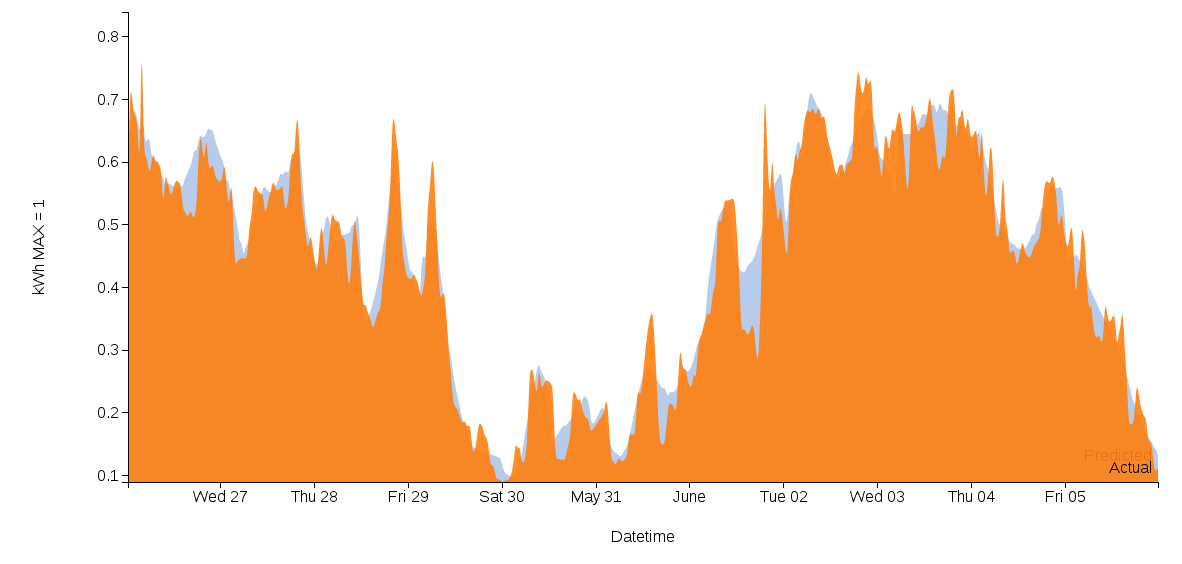 |
| Training results (orange=actual, blue=trained) |
Compiling emergent v7 and emergent v8 emergent has a new version (v8) but because it is still pretty new, a lot of the development SolarQuant underway has been tested on a stable version (v7.01) which runs well on both Debian and Ubuntu Linux from my experience. And because emergent can run as graphical application or via the command line, it’s a great environment to try out new correlations in a once-off manner with the GUI on your workstation or laptop, or run scheduled training sessions overnight with cron scripting via the commandline. Changing between the two versions on the same boot OS I believe is possible... but just to keep things clean and working, I have separated the two boot partitions. You wouldn't think a laptop could be powerful enough to run a massive compute intensive program like emergent, but it runs fine alongside a LAMP server on a $269 (USD) Dell Inspiron 14. I recently saw this machine however, and thought it might be a great workstation for this kind of work. And depending on how fast this GTX750Ti is, it may be something to start saving for - the GTX1060 has 1920 cores! - a multiple of 3 from Taniwha Two. Taniwha Three perhaps? In each of the emergent runtimes, you can set the number of epochs you want to run through - which is essentially how many times you go through your data set, and then batches of these epochs. You can see those 3 falling peaks in the chart above - those are batches. You can even split those batches across multiple processors I understand for further scalability, although I have not tried this yet. After each successful run, you can also output the weights matrix that your network finally got to - these small files hold the cumulative product of the training. You reference this weights matrix when you want to bounce new data off a trained network to get an "answer". Rebuilding my Back-Propagation network The only "algorithm" within emergent that can currently take advantage of the CUDA framework is the "bp" or Back-Propagation algorithm. While not the most advanced out there, it is probably appropriate for these kinds of time series experiments, and luckily that is what I've been testing with in SolarQuant. One of the cool aspects of emergent is that it contains a whole scripting language of its own which you can use to customise what you want it to do when your network project gets loaded. By passing arguments to the command line for emergent, you can tell it which program you want to run, which batches you want to run, and other important information like input data files to work with or matrix weights to start with. Because version 8 is a whole new build, the project file that I developed in v7 cannot be simply opened in v8, but has to be “rebuilt” which is essentially creating it again, defining the layers and setting the programs, using the new GUI. We’ll see how that process goes, but I intend to be able to do side by side comparisons between Taniwha One and Taniwha Two. Next post: Check in on how we’re doing with performance testing in Part 2...
2 comments:
Rob Duff sent me here :-)
I saw this article on LinkedIn yesterday that you might find of interest in view of your GPU experiments:
https://www.oreilly.com/learning/build-a-super-fast-deep-learning-machine-for-under-1000
Thanks Maximillian and apologies for the delay - yes that's a great resource! I think there's a lot of good crunching that could be done on that hardware and hopefully it's dropping in price further with the release of the latest 1080ti:
https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1080-ti/
Post a Comment